Scanning for broken Wix links
What do you do when a WordPress to Wix migration leaves you with 700 posts sprinkled with broken links? (Part 1: Find them)
I'm working this week to help a volunteer client (er.. I'm volunteering, not them) with their website. They had someone do a WordPress to Wix migration, and while their new site looks beautiful, when you dig in a few pages deep, there's still work to do.
My client had 10+ years of blog posts that their previous volunteer imported. The imports pretty much look fine, but many of those blog posts referenced other blog posts, with a mixture of URL formats, including the archive format from WP like domain.com/2012/02/04/pageslughere. Those are now mostly at domain.com/pageslughere. Except that sometimes pageslughere is not quite the same due to getting truncated differently (Wix likes 96 characters?), or having an apostrophe in the title that was handled differently, or... well, you get the idea. It's a bit of a mess, and there are 700+ blog post pages. So we needed some automation to find them, and then we'll need more to fix them.
How to find them:
1) You need Node & pm installed. I'm running everything on my local machine which I use for development anyway, so I didn't need to do anything extra here.
2) You need this broken link checker. I installed it in an empty directory with
npm install broken-link-checker3) Make a new javascript file in that directory. Here's mine:
var { SiteChecker } = require("broken-link-checker");
const siteChecker = new SiteChecker(
{
excludeInternalLinks: false,
excludeExternalLinks: false,
filterLevel: 3,
acceptedSchemes: ["http", "https"],
// Add any sites that are giving false positives false positives.
excludedKeywords: ["linkedin"]
},
{
"error": (error) => {
console.error(error);
},
"html": (tree, robots, response, pageURL, customData) => {
// Remove this line below if you don't want pages logged as they're scanned
console.log('Scanning page:', pageURL)
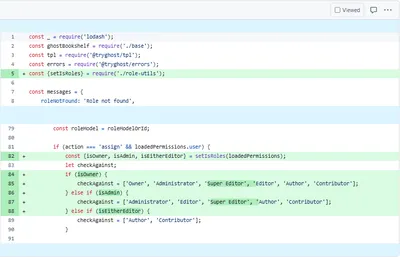
// This mess below is specific to the structure of the Wix page I was working with. I /think/ it's generalizable. I hope so, because it's an hour of my life I'm not getting back.
try{ let myNode = tree.childNodes[1].childNodes[2].childNodes[17].childNodes[0].childNodes[2].childNodes[0].childNodes[1].childNodes[0].childNodes[0].childNodes[0].childNodes[1].childNodes[0].childNodes[0].childNodes[0].childNodes[0].childNodes[1].childNodes[0].childNodes[0].childNodes[0].childNodes[0].childNodes[0].childNodes[0].childNodes[3].childNodes[1]
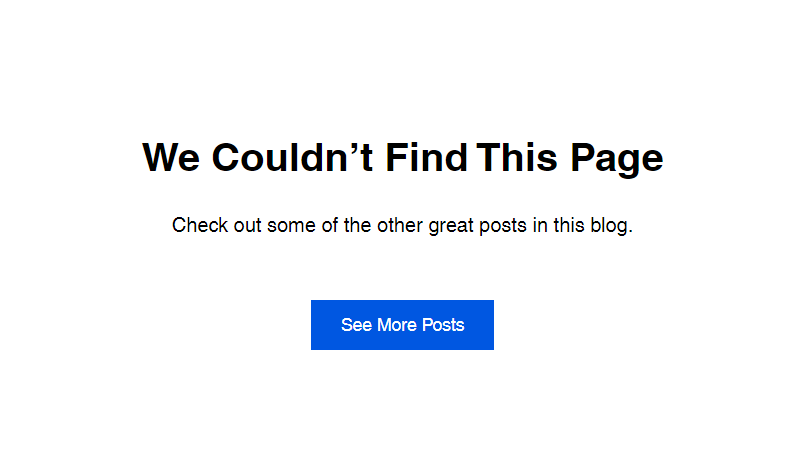
if (myNode.attrs[1].value == 'not-found-page'){
// What specifically to log if you get a "wix friendly error"
console.log("WIX_PAGE_NOT_FOUND => ", pageURL)}
}
catch {
//console.log('not a blog page')
}
},
"link": (result, customData) => {
if(result.broken) {
if(result.http.response && ![undefined, 200].includes(result.http.response.statusCode)) {
// What to log if you get a non-200 status code (mostly 404s)
console.log(`${result.http.response.statusCode} => ${result.url.original}`);
}
}
},
"end": () => {
// I find that sometimes I don't get this final log and the code just stops. Not sure why at this point.
console.log("COMPLETED!");
}
}
);
// be sure to update code below for your actual domain.
siteChecker.enqueue("https://domain.to.scan/");
4) And then I run it like this:
node thatjsfileabove.js > outputfile.txtThat writes turns those console.logs into an outputfile.
Here's documentation for the broken-link-checker:
 stevenvachon
stevenvachonI'm also deeply grateful to the author of the page below, which provided the code and options for a 'typical' scanning case, that got me closer to my special Wix case:
 Nic Raboy
Nic Raboy
If you try it, please let me know if it works for you! I only have one big Wix site to test on, so I'm not sure how generalizable my solution is.